
Pablo Romeo
Co-Founder & CTO
Generative AI is transforming our approach to creativity and problem-solving, making the comprehension of how it works increasingly vital.
As we integrate Large Language Models (LLMs) more in our daily tasks, we must clarify the doubts that build up around it. Why do AI models provide false information? What is the meaning of “AI hallucinations”? Is it possible to tailor AI models to specific needs?
If we want to know the potential and limitations of this emerging technology, it is important to explain and reflect on different concepts from a technical point of view. The principle is simple: when we understand how something works, we can make better use of it.
That is what we are aiming at with this article. Continue reading to boost your knowledge and leverage the power of Generative AI.
At the heart of modern artificial intelligence lies an innovative tool known as Large Language Models, or LLMs for short. The basic function of an LLM is to take a text—or “prompt”—as input and generate an output based on the parameters of the model—known as “ language patterns”—and the information they have learned over time.
These models need training and fine tuning to improve their accuracy. They use statistical finesse rather than true human comprehension to anticipate “what word should come next” in their output.
To be precise, LLMs don’t actually output words, they output tokens instead, which can be thought of as pieces of words. But in this article, we’ll just refer to the output as words, for simplicity.
It is important to understand LLMs are designed to produce fluent and coherent text. But they do not understand the underlying reality of what they are describing. AI models are based on probability, not accuracy. They predict what the next word will be, but they do not learn the meaning. Modern AI models are mimicking the art of language, not grasping its essence. They operate on the principles of probability, not truth.
While machines can perform increasingly complex tasks and AI models can learn and adapt, the question of whether they possess "intelligence" like humans is still a philosophical one. We can say AI models project an illusion of intelligence, as the result of intricate algorithms calculating the odds of word patterns, but not due to a real understanding—at least in the way us humans conceive it. Though LLMs can simulate human intelligence, they do not possess consciousness or self-awareness. At least not yet.
Why do AI models provide false information sometimes? Do AI models have the ability to create random responses?
Many people wonder about this, and to answer these questions we need to understand some parameters and key concepts of Large Language Models.
LLM parameters define the behavior of an AI model to determine how it will process input and how it will formulate output, with the goal of generating human-like text.
But what happens when the AI model “hallucinates”?
As explained by Andrej Karpathy, AI developer at Open AI and one of its founding members: "Hallucination is not a bug, it is LLM's greatest feature”, referring to the complex system of the LLM itself.
Now, regarding LLM assistants—like ChatGPT—where people write prompts and expect to get correct answers, Karpathy says: “The LLM Assistant has a hallucination problem, and we should fix it”. As he makes clear, LLMs and LLM assistants are two separate things.
As users of LLMs Assistants, if we are expecting to have a precise and correct answer, we should always verify the information they provide us as output. And LLM Assistants should always provide users with the proper Sources used in their answers.
Now, to understand more about hallucinations, temperature and accuracy let’s review each concept separately.
We say that an AI “hallucinates'' when it generates false, inaccurate, or illogical information. However, as said by Karpathy: "It looks like a bug, but it is just the LLM doing what it always does”.
AI models do what they have to do. They create something from scratch as we humans do in dreams. Sometimes our dreams are coherent, and sometimes not so much. But we cannot say they are “correct” or “incorrect” (from the point of view of an LLM).
However, if we build an application using an LLM where facts and precise data do matter, model grounding—a concept we will see later—is necessary so that we delimit where and how much it can “hallucinate”.
One example when AI models might hallucinate or give an incorrect answer is around geospatial knowledge, such as proximity, directions, and distances. But it depends on how this model was trained and with what information. Let’s see the next example where ChatGPT 3.5 is more prone to hallucination than ChatGPT4 with the same question:

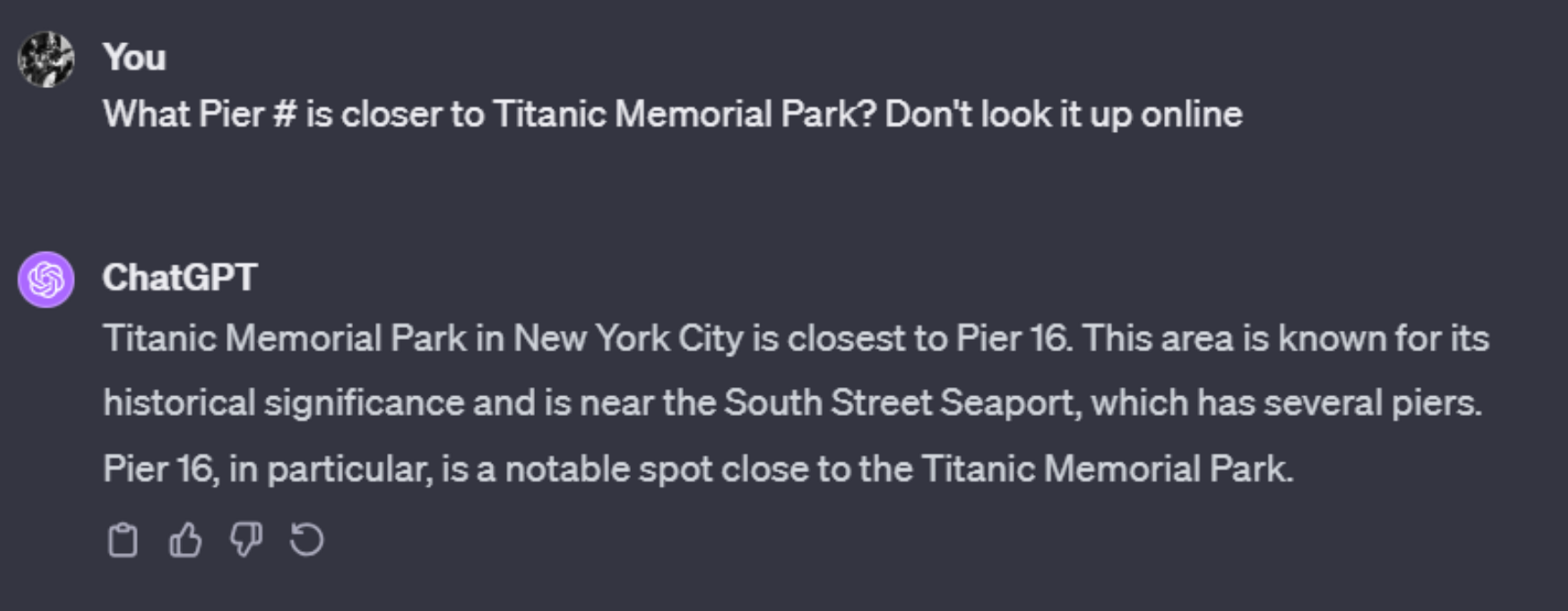
Now, GPT3.5’s answer is interesting because it mentions Pier 54. Which at first sight might seem completely unrelated. However, I suspect the reason it’s providing that as an answer, is because in its training data, the concepts of the Titanic and Pier 54 are indeed related. Pier 54 is where Titanic’s survivors finally arrived.
AI temperature is a parameter that controls the randomness of an AI model’s output. Temperature plays a critical role to determine the degree of hallucination a model has, or how creative its responses can be. When AI temperature is low, the outputs will be more deterministic and mostly predictable. If AI temperature is high, the model is more likely to generate random responses and hallucinate.
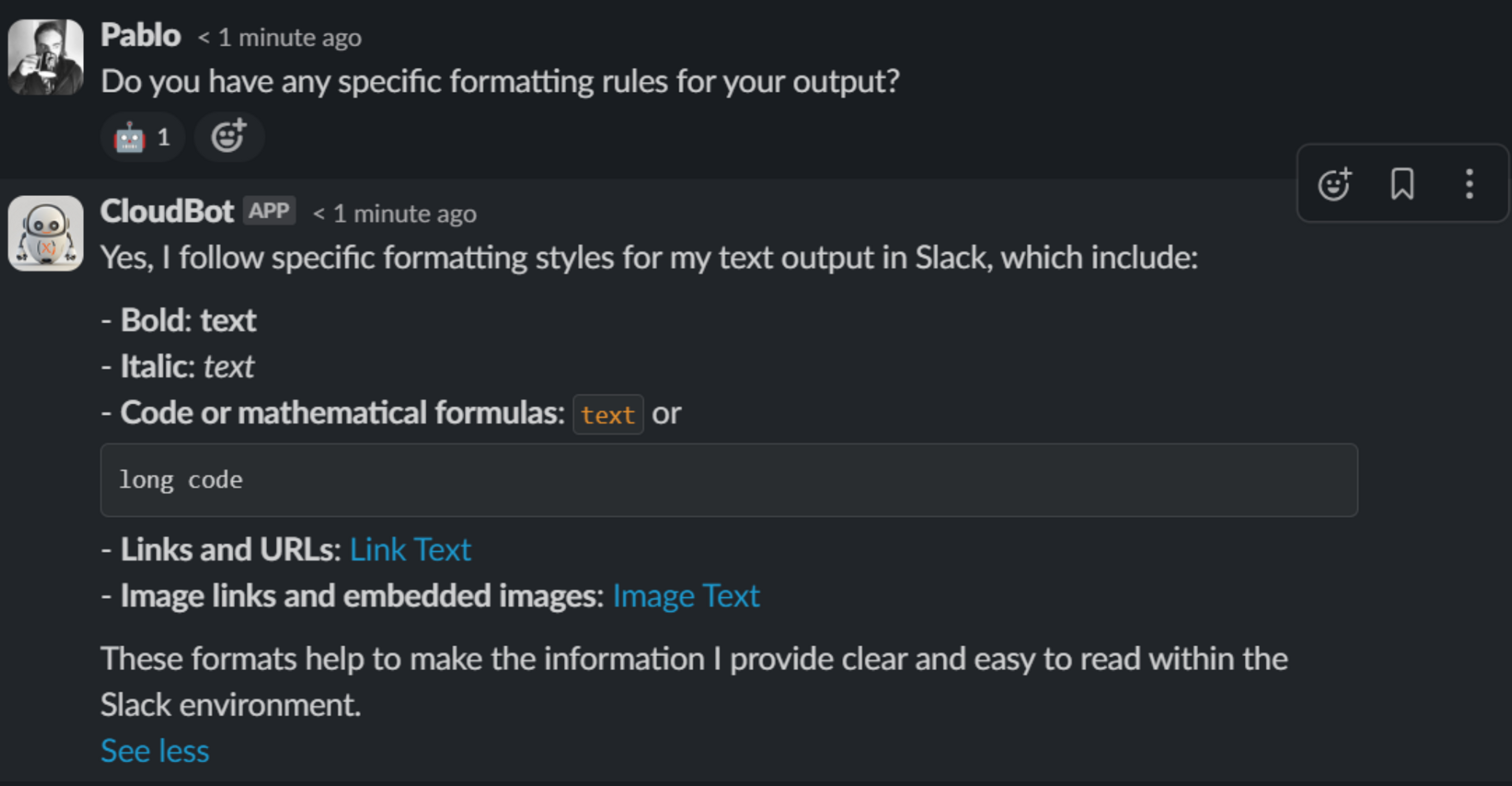
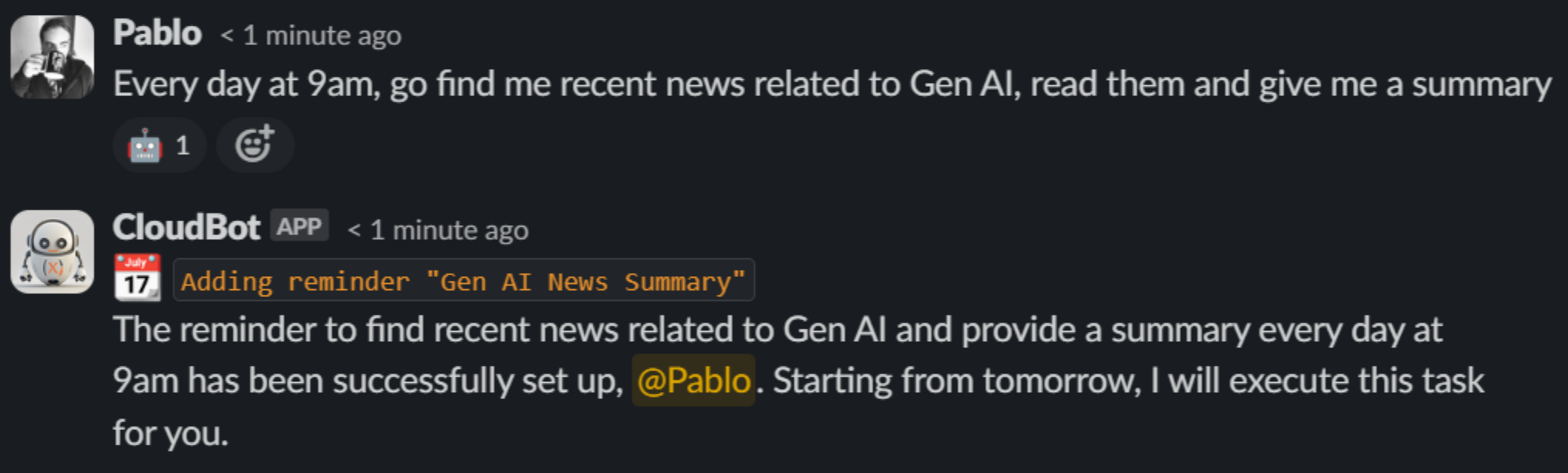
In the following examples we asked CloudBot—CloudX’s own AI assistant integrated in Slack—the same question but adjusting the model with different temperatures.
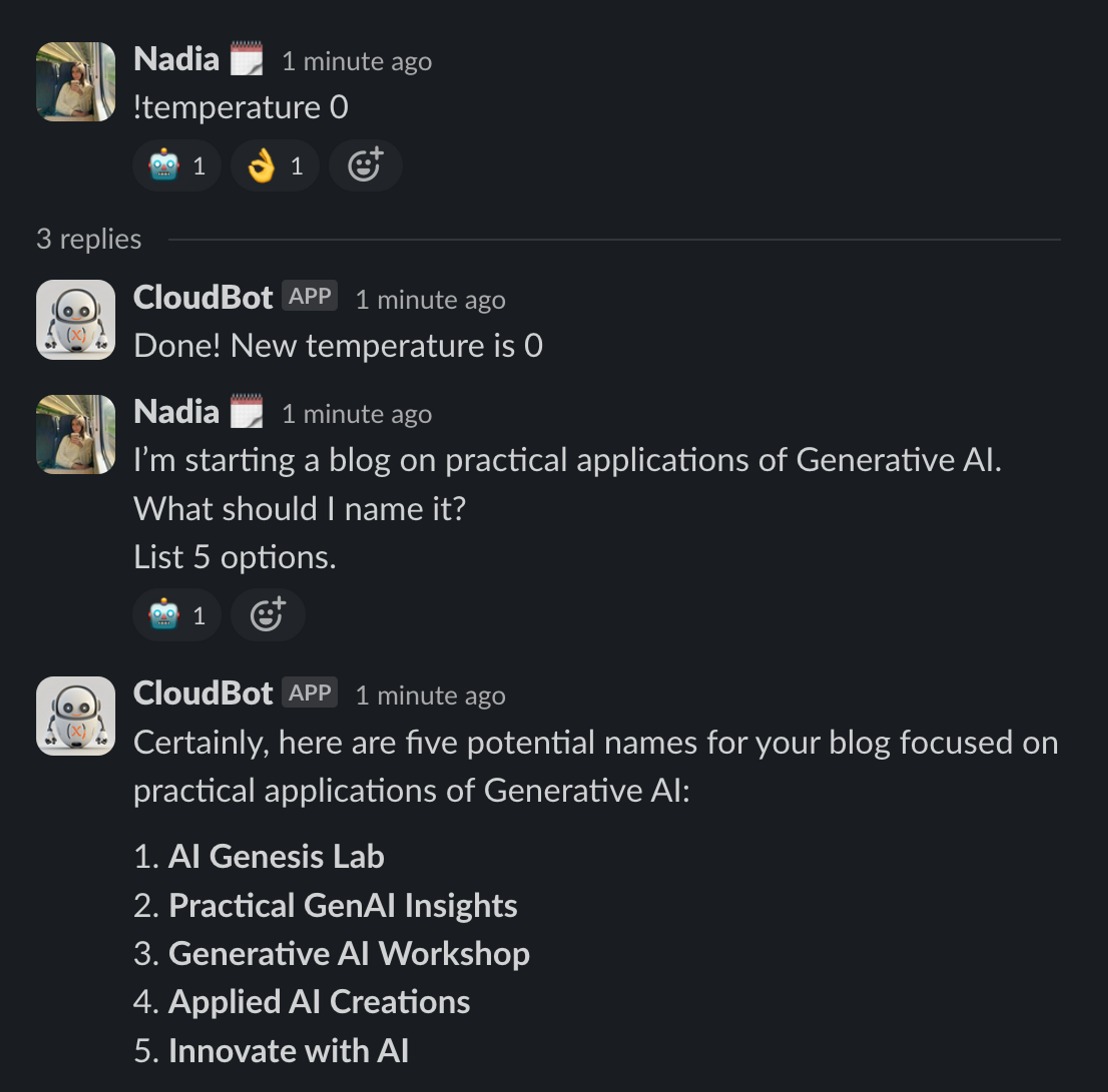
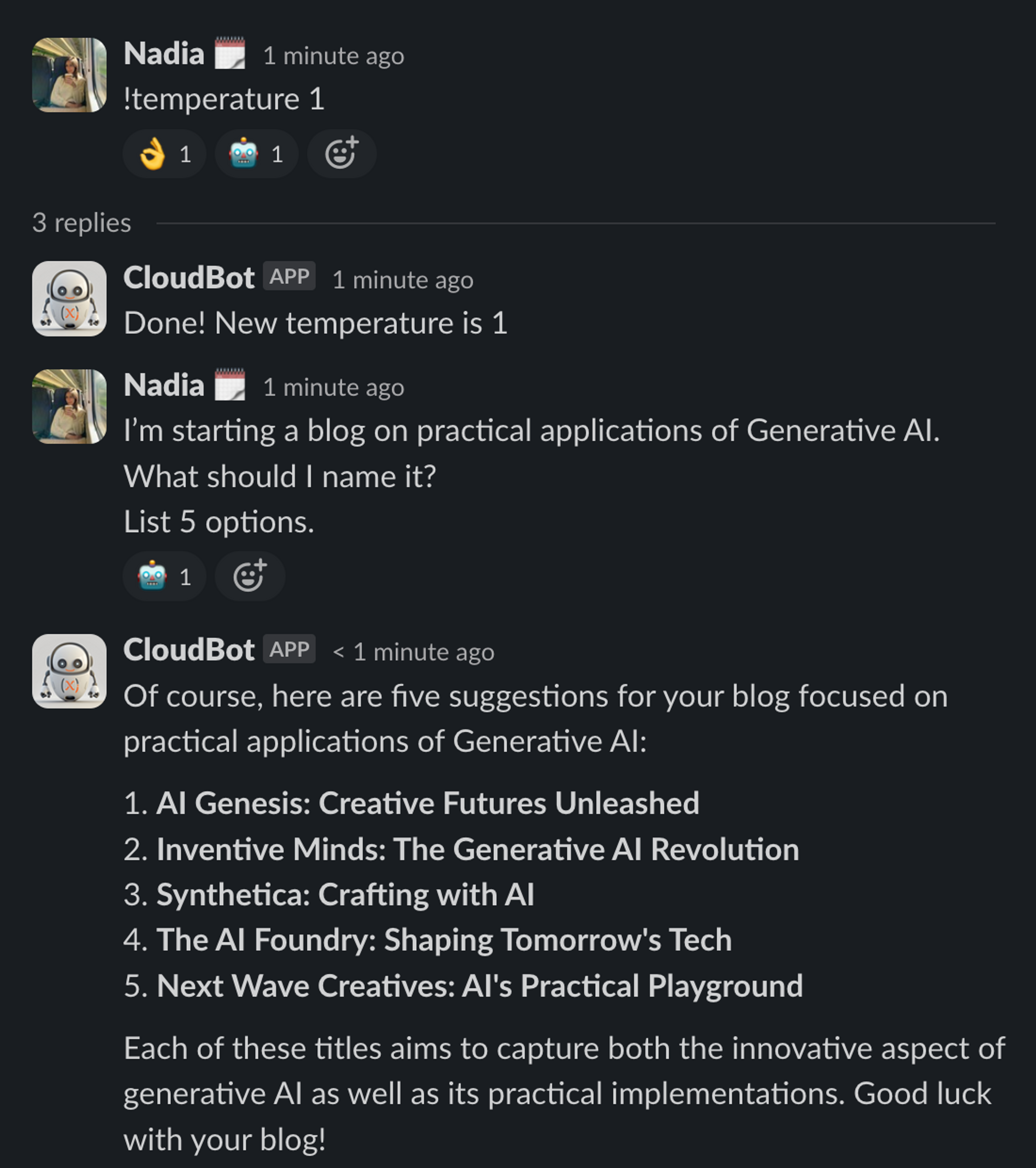
The temperature parameter plays an important part in how an LLM selects the next word in its output. When the temperature is set to 0 it will always choose the most probable word of a list of possible words to complete the sentence. As the temperature goes higher the chances of the LLM selecting a word other than the most probable one raise, which makes the output more random and less predictable.
As developers or users of an LLM, we should try to find the sweet spot of temperature according to our needs. If the temperature is set too low the output may seem too “robotic”, but if it is set too high the response might be irrelevant to the input it was given and even be incoherent if raised too high.
AI accuracy indicates the degree to which a model produces correct outputs or predictions based on the given input. Accuracy is an important metric in machine learning for evaluating model performance, as it is often used as a primary indicator of the quality and effectiveness of an AI model.
This can be measured in various ways depending on the task at hand, but generally, accuracy is about the model's ability to generate responses that are factually true, contextually relevant, grammatically correct, and coherent.
Accuracy is important in LLMs to ensure if we can trust or not in the information we are given, if it is useful for what we want to use it for, and it is also an indicator of a well-trained AI system. If we see it from a technical point of view, high accuracy means that the model has learned effectively from its training data and can generalize well to new, unseen data.
Fine-tuning is a technique that allows us to start with a pre-trained model and customize it for our own specific requirements, such as:
The purpose of fine-tuning is to adapt the model to a specific task or domain without having to train the model from scratch.
Fine-tuning also has the added advantage of allowing us to reduce the amount of tokens needed for system instructions, and therefore, reducing costs.
Model grounding is the process of providing specific and relevant information to LLMs to improve the accuracy and relevance of their output. AI models have general knowledge but need grounding to incorporate up-to-date and use-case-specific information.
Grounding an AI model is about connecting the abstract concepts it has learned to real-world entities and scenarios. It involves ensuring that the model's outputs are meaningful in a specific context.
There are several strategies to accomplish this, the most popular being:
In-context learning (ICL) uses task demonstrations within prompts to leverage a pre-trained LLM for solving new tasks, without fine-tuning the model. This is how an AI model can adapt to new information presented in the input it receives at the moment of use.
In-context learning is a significant advancement in AI because it allows for more flexible and interactive use of AI models, enabling them to perform a wide variety of tasks without the need for task-specific training data.
While in-context learning is powerful, it has limitations. The model's understanding is constrained by the context window—the amount of text it can consider at one time—, and it may not always infer the correct intent or have the depth of understanding that comes from specialized training.
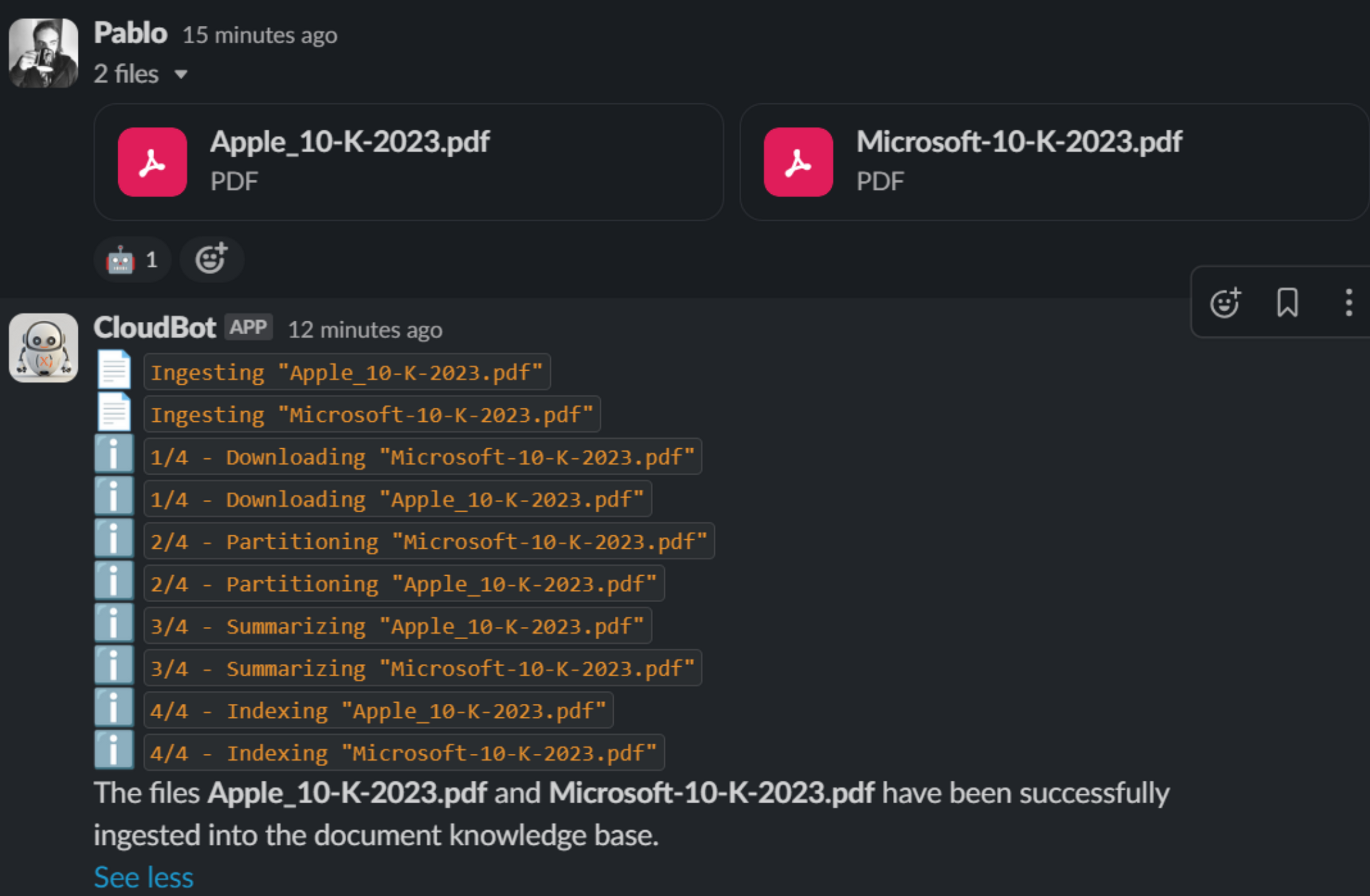
Given that this is a huge topic, we will dive deeper in separate articles, but the gist of it is to have a mechanism to provide relevant information from a “relatively static” set of external sources.
Commonly a very basic implementation of RAG implies previously indexing documents—PDFs, presentations, spreadsheets, etc.—into Vector Databases and using Semantic Search to find relevant parts of documents, which are given to the LLM to formulate its response.
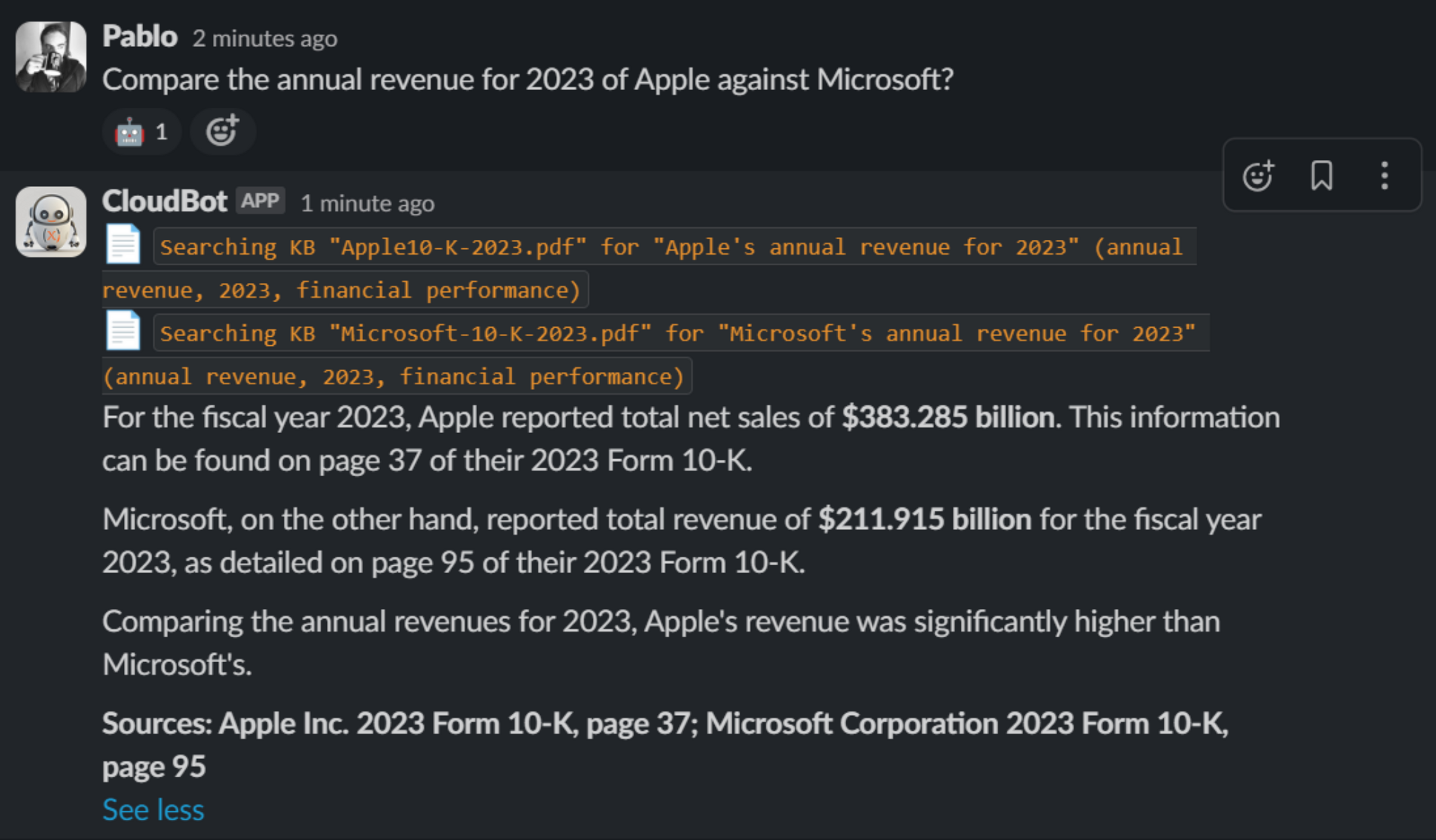
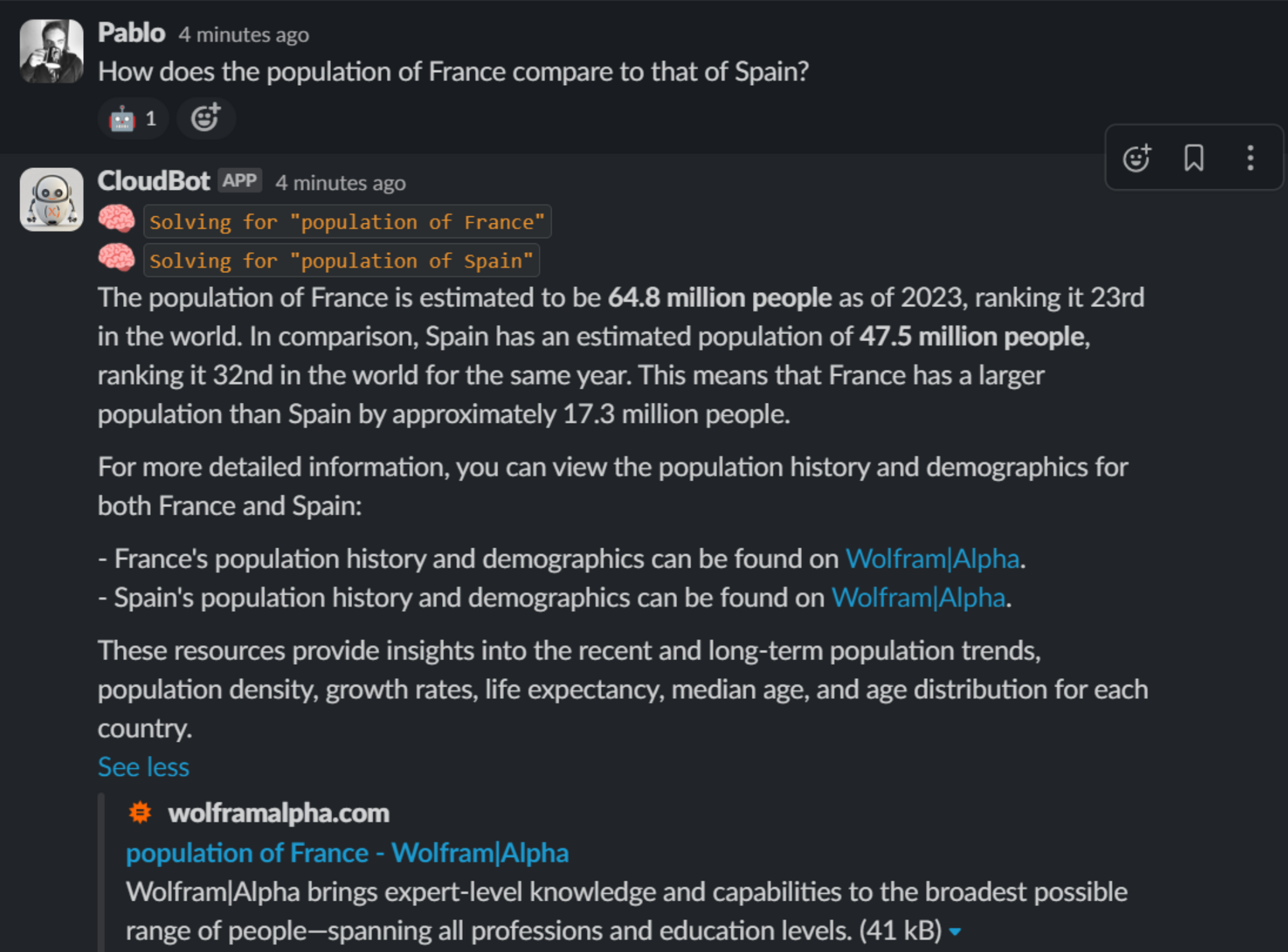
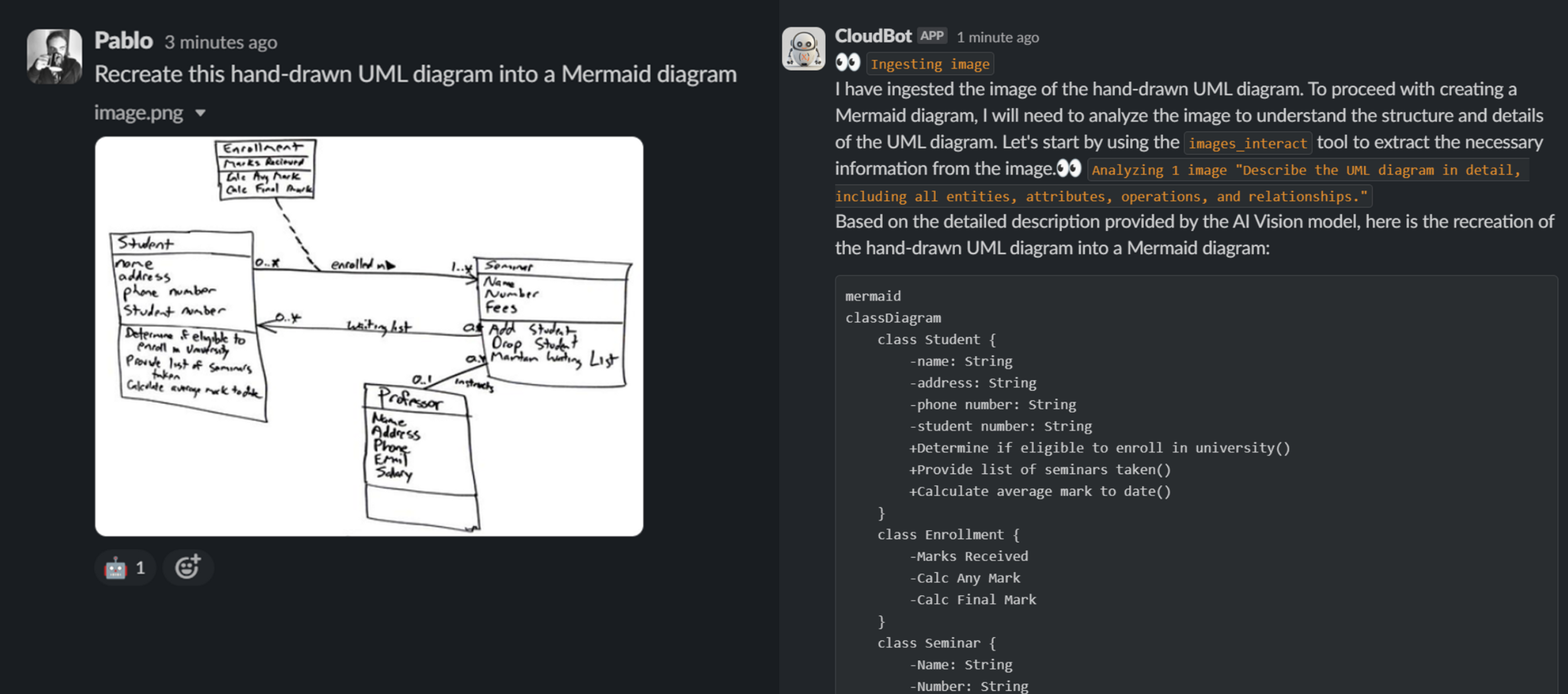
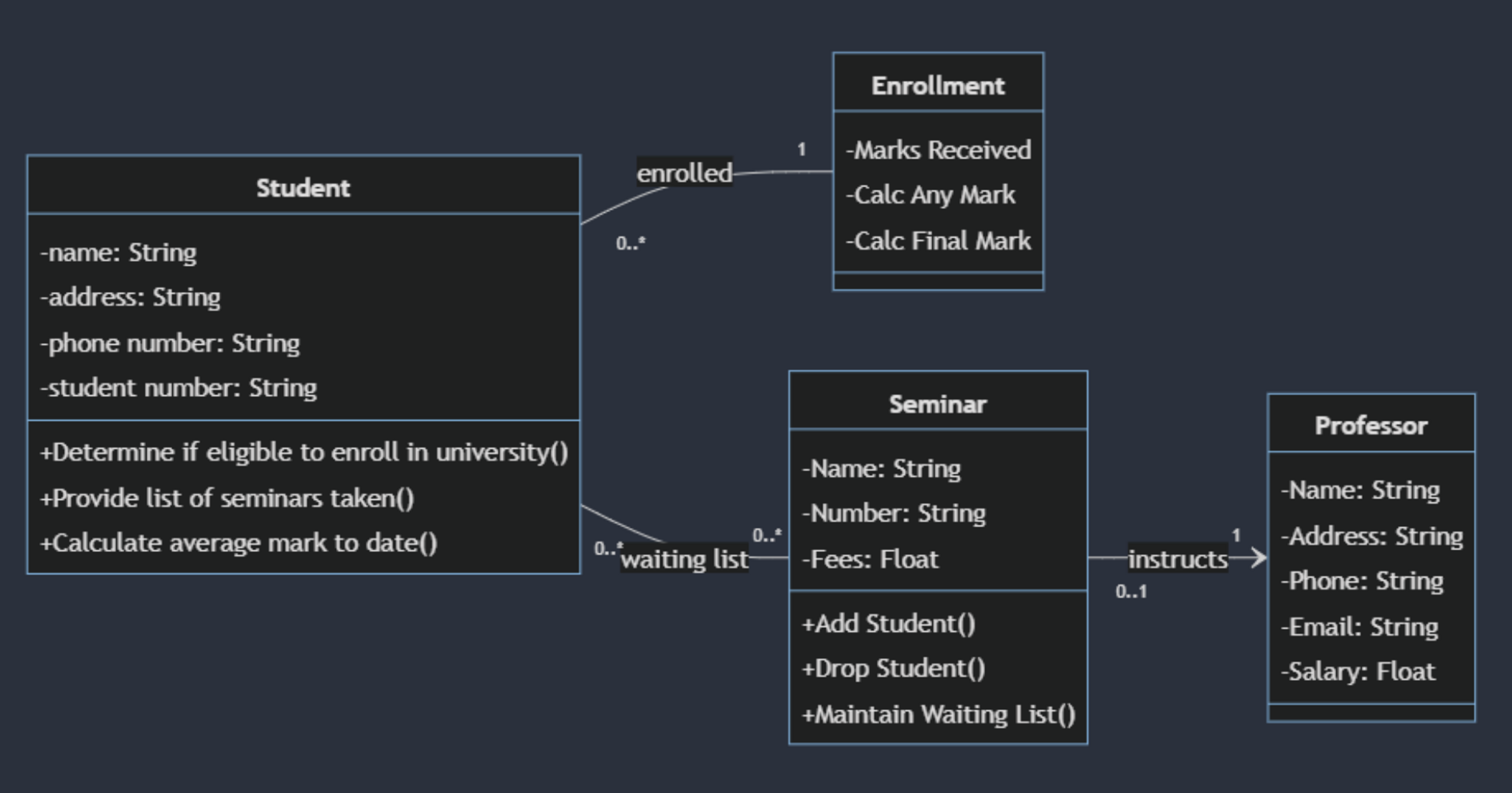
This approach shares the overall objective of RAG, but it is more around extending the capabilities of LLMs by providing it access to additional tools. Not just to fetch information but also to interact with the world.
Tools can be pretty much anything, given that ultimately they are just code you yourself create.
Common examples are:
Understanding Generative AI and how Large Language Models (LLMs) work is the best way to take advantage of this new technology.
For example, being aware of how prone an AI model is to hallucinate, will be key to know how accurate its answers will be. It is also important to know that with fine-tuning an AI model can be given a certain tone and personality that will determine “how” an output is given. And to be able to get more relevant and accurate responses as well extending the models capabilities, you can rely on in-context learning (ICL), RAG or additional tooling.
By approaching AI with curiosity and a commitment to continuous learning we will be able to harness its capabilities to the fullest.

Service
We implant AI into your ecosystem in a way that adds real value to your business, designing and implementing a solution specifically tailored for your…

Insights
We have been talking about Artificial Intelligence for at least half a century. So, what is the hype? How is the new AI different from traditional AI? In this…

Insights
The Data & Analytics Maturity Curve is a powerful framework that helps organizations assess their data maturity and remove the most common blockers to AI…